Brad Fitzpatrick
Winter 2002
LiveJournal.com is an online community site where people write in their journals, and reply to and read other people's journals. LiveJournal continues to grow, currently with about 500,000 users. Unfortunately, the back-end architecture that powers the site has been performing with increasingly less efficiency over time as the site grows. The architecture has been tweaked over time to get better performance, but it's always remained pretty much the same.
My responsibility with LiveJournal.com over the past few months has been redesigning the back-end database architecture.
The basic problem was that the existing infrastructure didn't scale. That is, as LiveJournal purchased more servers to accommodate more users, each server's positive effect was worth less than the one before it. The ideal is to be able to simply double the number of servers and then be able to handle double the number of users, and so on.
I'll explain the initial configuration, its faults, how I redesigned it, and then the migration plan and implementation to transition the back-end while maintaining minimal downtime.
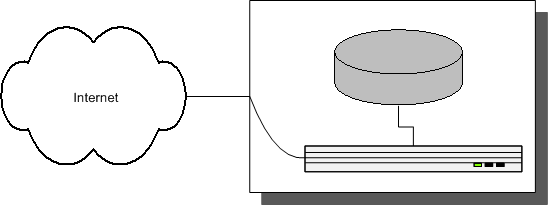
In the very early days, LiveJournal.com ran on one physical server. That server ran both the database software and the web server. A user would request a webpage, that request would go to the web server, the web server would invoke the program to generate the web page, which would almost always involve the program first talking to the database server (running on the same physical server). See Fig. 1.
Soon, that one physical server became too busy, so the next logical step was to have two machines: one running the web server, and one running the database.
The hardware requirements for a web server versus a database server are very different. The database server holds a lot of critical data, so it must be very reliable. It also uses its disks a lot, so there should a be lot of them, for both speed and redundancy in case of failure. In fact, one should have hot-swappable redundancy in every component of the system. Most good server hardware has hot-swappable power supplies, even. At LiveJournal's host, both power supplies are plugged into separate power strips, each of which is backed by huge battery-powered backup power systems (UPS) which kick in when the city power fails. This is important because a server (or any computer, really) should never be powered off without being shut down properly. For speed, computers don't write out to disk everything immediately: they do it in batches when they have free time. If the power is turned off without a proper shutdown, then data can get lost.
A web server is cheap by comparison. It stores no critical data, so it isn't necessary to have redundancy on every level. The only thing important is speed to run the programs which generate the pages.
LiveJournal's architecture after buying a dedicated DB server then looked like this:
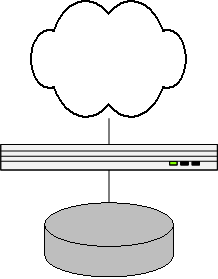
Generally, a fully redundant database server is going to be expensive. To avoid upgrading it too soon, it's usually better to spend even more money on it, beefing it up to the point where it'll last surely quite awhile. As such, the next bottleneck LiveJournal hit wasn't the database, but the much cheaper web server.
Fortunately, scaling web servers when the web server stores all its state & data in the database is easy: just add more web servers. That part scales beautifully.
The only challenge in scaling web servers is that there needs to be a mechanism to redirect web requests to the least busy or most capable machine. Such mechanisms are called load balancers and can be either hardware or software. Good hardware load balancers cost upwards of $25,000 alone. What is worse is that one almost has to buy them in a pair for redundancy. What's the point of having redundancy everywhere only to have the load balancer be a single point of failure, die, and leave the entire site down? At this point, though, LiveJournal didn't have $50,000 for two load balancers. We ended up using a software solution, using mod_backhand (http://www.backhand.org/), whereby each web server would broadcast to the others its status, and if a server felt it was too busy and another machine could better handle the request, it would transfer it behind the scenes, without the end user knowing it was happening.
Software load balancers aren't without their problems, though. After the end user types in livejournal.com, his/her browser then looks up the server's IP address and tries to connect to it. If there are two web servers, each needs its own IP address. When one configures DNS (host name to IP address mapping service), which IP address does the name livejournal.com point at? One solution is to do round-robin DNS, but then if a machine dies, every other request goes nowhere, since the target machine is dead.
A better solution is to give each web server a private IP address which they use to talk amongst themselves and transfer load between, and then use one virtual public IP address on a single machine that's alive. DNS is then configured such that the domain name points at that virtual IP. There's a tool called "Wackamole" from the same people that make mod_backhand to automatically handle setting up this virtual address on any machine that's alive at a given time. Unfortunately, that wasn't released until well after we'd passed this stage in our growth, so we managed the public IP address assignment by hand whenever a machine died (very rarely) or when we had to do maintenance on a machine (more often the case).
After adding our two new servers (we generally buy servers in pairs), our infrastructure looked like this:
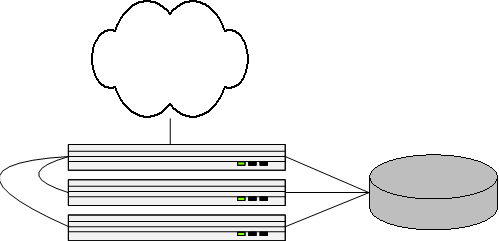
We now had more than enough web server capacity. The next bottleneck was our database server. Database servers by comparison are extremely difficult to scale. The database contains one huge representation of all information, all intertwined and interdependent. In a relational database, one usually get information by selecting data from many tables at once. Most database engines require that the tables live on the same physical machine if they're both going to be used at once to answer a query.
If a second server is added, what is its role? How does it help out?
The database software we use, MySQL (http://www.mysql.com/), lets a database server be defined as a "Master" from which "Slave" database servers connect to and replicate changes from. The application code then sends all database changes to the master, and then the slaves play catch-up continually, feeding off the master database's changelog. The slave database is generally only about a half second behind.... more than adequate for all but a few things in the code, those of which can just rely on the master only.
So we stopped the site, made a full copy of the database data from the master to the slave, then started both up. Now both databases were consistent, and in sync with each other.
Database traffic comes in two types: read and writes. When people write in their journal or reply to other people's journals, a write request goes to the database, to save that information. This type of request has to go to the master so it is replicated to the slave database.
The cool thing at this point, with the slave replicating, is that read requests (people reading journals or reading comments) can be directed to either the master or the slave.
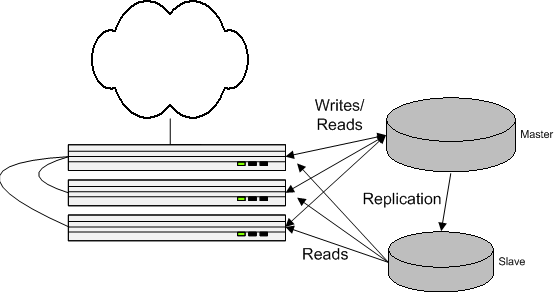
This isn't as nice as the scaling of the web servers, though. Even though we're splitting the read requests evenly amongst the number of database machines we add, each one still has to process all the writes.
Clearly, scaling the database like this wouldn't work for long. We knew this at the time, but it was the simplest thing to do. Eventually, our infrastructure grew to this:
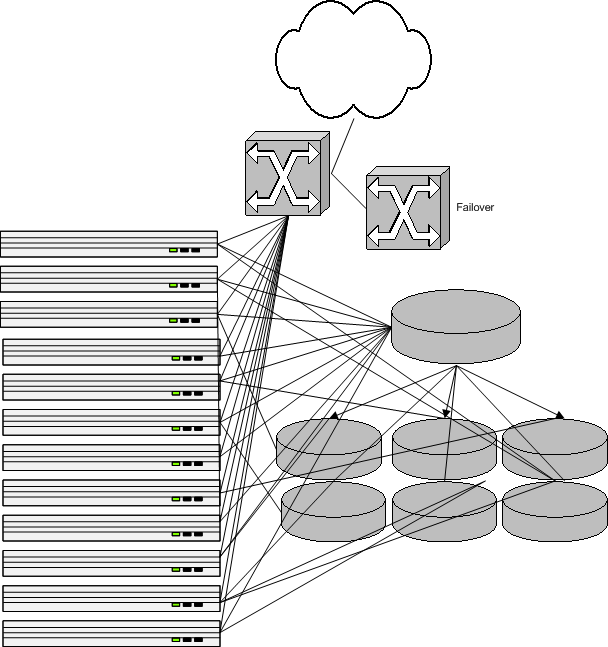
Look chaotic? It was, pretty much.
We picked up two hardware load balancers along the way from two different bankrupt IPO-hype dot-com busts, at about 90% off retail price. The second one is just a hot spare which kicks in in case the primary one dies. It's important to avoid a having a single point of failure. After all, the architecture is only as good as its weakest link.
Even with all this hardware, LiveJournal started to perform incredibly poorly. The reason was pretty obvious, as I stated above: every write sent to the master database was propogating to every slave.
For purposes of demonstration, let's imagine that each end user does on average 75% reads and 25% writes. We actually didn't measure this split because a) it's somewhat difficult to figure, and b) it just doesn't matter --- the asymptotic behavior doesn't change. Eventually the limit will be reached and the site will hit a wall. (And LiveJournal did... more on that later.)
So given the hypothetical read/write split above, let's see how well this configuration scales. A further constraint is that a given database server can only do so much at once. Let's make up some more numbers and imagine a single database can do 1000 units of work at once, with reads taking 1 unit, and writes taking 2 units.
| Web request/s: | 100 | 200 | 300 | 400 | 500 | 600 | 700 | 800 | 900 | 1000 |
| DB Writes/s: | 25 | 50 | 75 | 100 | 125 | 150 | 175 | 200 | 225 | 250 |
| DB Reads/s: | 75 | 150 | 225 | 300 | 375 | 450 | 525 | 600 | 675 | 750 |
| DB Write Work/s: | 50 | 100 | 150 | 200 | 250 | 300 | 350 | 400 | 450 | 500 |
| DB Read Work/s: | 75 | 150 | 225 | 300 | 375 | 450 | 525 | 600 | 675 | 750 |
| Total DB Work/s: | 125 | 250 | 375 | 500 | 625 | 750 | 875 | 1000 | 1125 | 1250 |
So this hypothetical one-database configuration maxes out at 800 web requests per second.
| Web request/s: | 100 | 200 | 300 | 400 | 500 | 600 | 700 | 800 | 900 | 1000 | 1100 | 1200 |
| DB Writes/s: | 25 | 50 | 75 | 100 | 125 | 150 | 175 | 200 | 225 | 250 | 275 | 300 |
| DB Reads/s: | 38 | 75 | 113 | 150 | 188 | 225 | 263 | 300 | 338 | 375 | 413 | 450 |
| DB Write Work/s: | 50 | 100 | 150 | 200 | 250 | 300 | 350 | 400 | 450 | 500 | 550 | 600 |
| DB Read Work/s: | 38 | 75 | 113 | 150 | 188 | 225 | 263 | 300 | 338 | 375 | 413 | 450 |
| Total DB Work/s: | 88 | 175 | 263 | 350 | 438 | 525 | 613 | 700 | 788 | 875 | 963 | 1050 |
See how writes/second per database stayed the same? Only reads/second dropped in half. So now we can handle our 1000 units of work a second without dying, but not for long.
Here's a graph showing the units of work required per server per second for 1-7 servers. Notice that after the third server or so, there's really not much gain at all:
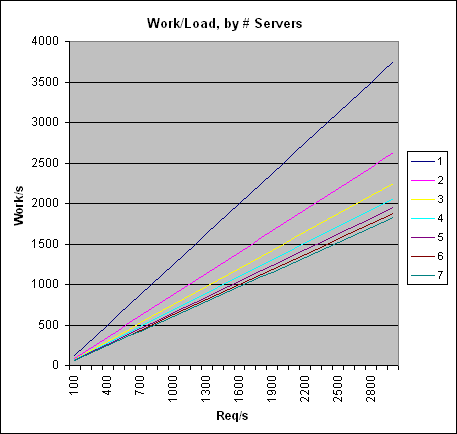
What's scarier though is to graph the diminishing return itself. Here's a graph showing the percentage load drop per server added, for 9 different values of read/write percentage. If the site never did writes, it'd scale just as easily as web servers. Unfortunately, we do writes, so we need to find a new solution to keep scaling.
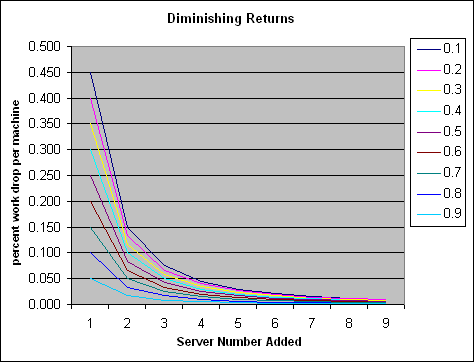
The graphs above only show the percentage gain each new server adds. Obviously adding new servers makes the situation better, not worse. But, the improvement is marginal over time:
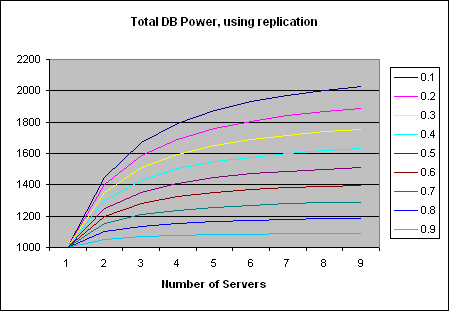
As the number of servers grows, the limit of total capacity over all servers is the point at which the slowest server can't keep up with just the writes. This is also explained in the MySQL FAQ at <http://www.mysql.com/doc/R/e/Replication_FAQ.html>. Basically, we could essentially eliminate reads with an infinite number of servers, but never eliminate writes.
Our site's growth rate looked like this:
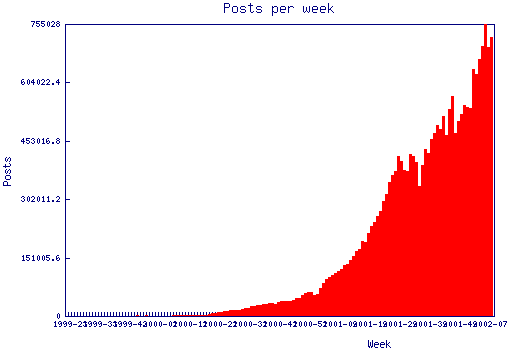
Notice how the growth curve is smooth when the servers were okay, and jagged when we were having problems. The scary thing is the growth is exponential but our DB power as we added new servers was logarithmic. A better back-end solution was needed.
The other problem with having every database record all changes is that the disk space requirements get absurd. At LiveJournal's peak, we had 42 GB of total data. While 42 GB of disk space is cheap in personal computers, server disk drives are a lot more expensive and are generally bought in excess of minimal needs, for both speed and reliability. Considering that each server only has so many drive bays to expand, buying new disks for each server as we grew was also a problem.
Yet another problem was that each server's performance goes down as the size of the data goes up, due to worse cache performance. Each DB server had between 2GB and 4GB of memory. The operating system and DB software use the memory for storing the most frequently access information in memory, which is orders of magnitude faster than disk drive access. As the dataset grows larger, a smaller percentage of it can lie in system memory at once.
To solve the disk space issue, I made each database slave only record the journal text and comment text for the past three weeks. Then I just had to modify the code to first check the slaves, and then read from the master only when the desired data wasn't on the slaves. This works because the bulk of the load is on the new content, so the master database never gets too loaded.
Still, each database server was doing way too much writing. Another temporary solution was to identify which database tables were never used from the slaves, and change the slave configurations to not replicate them. By default, it replicates all changes. This helps a bit, but not a ton. I noticed that the total size of all non-text data was about the same size of all the text data, so I decided to make one server only replicate the recent text tables, and make all the other slaves not replicate the recent text. Then, the code was changed to first try the recent text database server, then the master. This helped a bunch. The only problem is that if that one recent text database died, the master would be more loaded until we fixed the dead machine. Not a huge deal, though.
At this point it was obvious we were starting to give databases different roles. I changed the database connection code to support this idea cleanly.
So far, all my efforts to improve the site's performance could be considered stupid hacks, at best. The basic architecture (slaves replicating from a single master) was still the same.
The obvious thing to realize is that the site worked fine on one server at one point and there's no need for a person's journal to be stored on nine different database servers. At minimum, the data should be stored on two for reliability. Storing it on more is just wasting resources.
There's no reason why the site shouldn't be able to scale linearly. We should be able to double the number of servers and be able to support double the users. The key to achieving this goal was breaking up the databases. Just as the web servers were in no way dependent on each other, the database servers needed to be also.
The solution was to assign each user to a cluster of, at minimum, two database servers where all their journal entries, comments, pictures, and other data is stored. Instead of sending these writes to the top layer to trickle down the slaves, the web code was changed to know where to send writes. Site-wide writes that don't affect an individual user go to the top, as before, but user-specific writes go to that user's cluster master.
Earlier I mentioned we had the database server that had nothing but recent text. That was a great temporary hack... not only did it work wonderfully, but it made me realize the real solution, and it led me to rewrite the database connection code to support the idea of roles per server. Consider all the roles we now have:
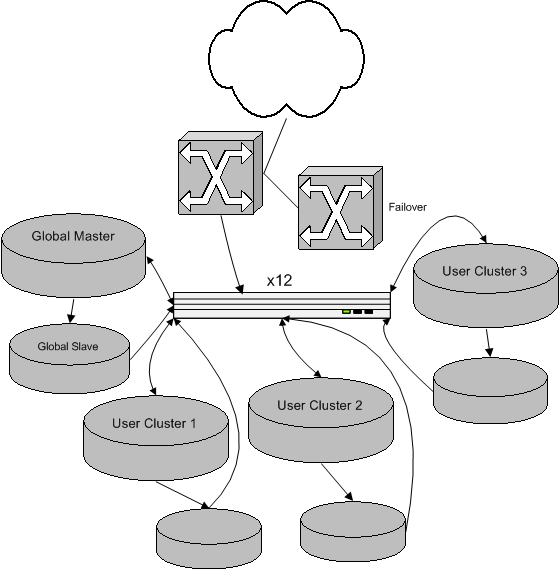
Now when new users are added, they're assigned to the least loaded cluster. When all clusters are sufficiently loaded, we just buy another two database servers and make a new cluster. If, for some reason, the users on a particular cluster get really busy and the cluster loads become unbalanced, we can easily move users between clusters to readjust the weighting.
The difficult part with this whole new scheme wasn't the implementation (that was easy), but rather the migration from the old schema to the new. Changes to the on-disk format of the data were required to support user clustering, and the time required to convert everything would've been about 35 days. Obviously we couldn't take the site down for 35 days, so what I did instead was make the codebase to support both the new tables and the old tables at the same time. If a user's clusterid was 0, that means their data lived on the site-wide cluster. Then in the background there's a process running now converting users 4-10 at a time (depending on time of day and site load) to the clusters. During a user's conversion, their journal is still readable, but they can't post new entries and others can't comment in their journal. A single conversion takes between a minute and 30 minutes, depending on the number of posts and comments.
With all the user-specific data moved to clusters, all that will remain in the site-wide database servers is about 1 GB, which is small enough to fit entirely in memory, for nearly instant read & write access. This will be a huge speed boost which we basically get for free.
Although a full conversion will take a month or more, the busiest journals are being converted first. After only a few days, the site was absolutely flying. As time goes on, the site keeps getting faster. I'm happy, and the users are happy.